来源:Tom's Hardware
原英文标题:《Nvidia Unveils Big Accelerator Memory: Solid-State Storage for GPUs》
Nvidia and IBM propose a new GPU-SSD interoperability framework.
Nvidia和IBM提出了一个新的GPU-SSD互操作性框架。

Microsoft's DirectStorage application programming interface (API) promises to improve the efficiency of GPU-to-SSD data transfers for games in a Windows environment, but Nvidia and its partners have found a way to make GPUs seamlessly work with SSDs without a proprietary API. The method, called Big Accelerator Memory (BaM), promises to be useful for various compute tasks, but it will be particularly useful for emerging workloads that use large datasets. Essentially, as GPUs get closer to CPUs in terms of programmability, they also need direct access to large storage devices.
微软的DirectStorage应用程序编程接口(API)承诺提高Windows环境中游戏的GPU到SSD数据传输的效率,但Nvidia及其合作伙伴已经找到了一种方法,使GPU在没有专有API的情况下与SSD无缝协作。该方法称为大规模存储加速器 (BaM),有望用于各种计算任务,但对于使用大型数据集的新兴工作负载尤其有用。从本质上讲,随着GPU在可编程性方面越来越接近CPU,它们还需要直接访问大型存储设备。
——
Modern graphics processing units aren't just for graphics; they're also used for various heavy-duty workloads like analytics, artificial intelligence, machine learning, and high-performance computing (HPC). To process large datasets efficiently, GPUs either need vast amounts of expensive special-purpose memory (e.g., HBM2, GDDR6, etc.) locally, or efficient access to solid-state storage. Modern compute GPUs already carry 80GB–128GB of HBM2E memory, and next-generation compute GPUs will expand local memory capacity. But dataset sizes are also increasing rapidly, so optimizing interoperability between GPUs and storage is important.
现代图形处理单元不仅适用于图形,它们还用于各种重型工作负载,如分析、人工智能、机器学习和高性能计算 (HPC)。为了有效地处理大型数据集,GPU要么需要在本地使用大量昂贵的专用内存(例如HBM2、GDDR6等),要么需要高效访问固态存储。现代计算 GPU 已经搭载了 80GB–128GB 的 HBM2E 内存,下一代计算 GPU 将扩展本地内存容量。但数据集大小也在迅速增加,因此优化 GPU 和存储之间的互操作性非常重要。
——
There are several key reasons why interoperability between GPUs and SSDs has to be improved. First, NVMe calls and data transfers put a lot of load on the CPU, which is inefficient from an overall performance and efficiency point of view. Second, CPU-GPU synchronization overhead and/or I/O traffic amplification significantly limits the effective storage bandwidth required by applications with huge datasets.
GPU和SSD之间的互操作性必须提高有几个关键原因。首先,NVMe调用和数据传输给CPU带来了很大的负担,从整体性能和效率的角度来看,这是低效的。其次,CPU-GPU 同步开销和/或 I/O 流量放大会显著限制具有庞大数据集的应用程序所需的有效存储带宽。
——
"The goal of Big Accelerator Memory is to extend GPU memory capacity and enhance the effective storage access bandwidth while providing high-level abstractions for the GPU threads to easily make on-demand, fine-grain access to massive data structures in the extended memory hierarchy," a description of the concept by Nvidia, IBM, and Cornell University cited by The Register reads.
"Big Accelerator Memory的目标是扩展GPU内存容量并增强有效的存储访问带宽,同时为GPU线程提供高级抽象,以便轻松按需,细粒度地访问扩展内存层次结构中的海量数据结构,"The Register引用的Nvidia,IBM和康奈尔大学对这一概念的描述写道。
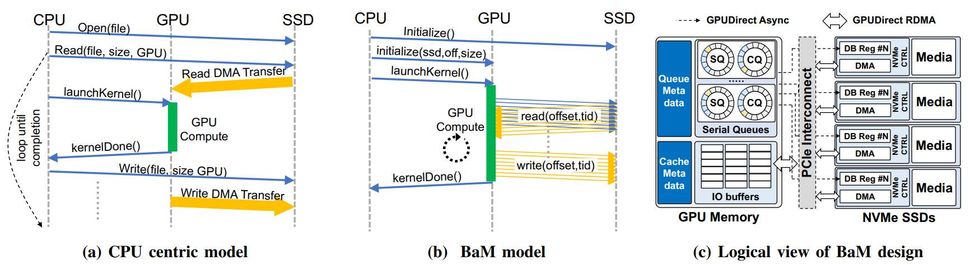
BaM essentially enables Nvidia GPU to fetch data directly from system memory and storage without using the CPU, which makes GPUs more self-sufficient than they are today. Compute GPUs continue to use local memory as software-managed cache, but will move data using a PCIe interface, RDMA, and a custom Linux kernel driver that enables SSDs to read and write GPU memory directly when needed. Commands for the SSDs are queued up by the GPU threads if the required data is not available locally. Meanwhile, BaM does not use virtual memory address translation and therefore does not experience serialization events like TLB misses. Nvidia and its partners plan to open-source the driver to allow others to use their BaM concept.
BaM基本上使Nvidia GPU能够直接从系统内存和存储中获取数据,而无需使用CPU,这使得GPU比现在更加自给自足。计算 GPU 继续使用本地内存作为软件管理的缓存,但将使用 PCIe 接口、RDMA 和自定义 Linux 内核驱动程序移动数据,该驱动程序使 SSD 能够在需要时直接读取和写入 GPU 内存。如果所需的数据在本地不可用,则 SSD 的命令将由 GPU 线程排队。同时,BaM 不使用虚拟内存地址转换,因此不会遇到 TLB 未命中等序列化事件。Nvidia及其合作伙伴计划开源驱动程序,以允许其他人使用他们的BaM概念。
——
"BaM mitigates the I/O traffic amplification by enabling the GPU threads to read or write small amounts of data on-demand, as determined by the compute," Nvidia's document reads. "We show that the BaM infrastructure software running on GPUs can identify and communicate the fine-grain accesses at a sufficiently high rate to fully utilize the underlying storage devices, even with consumer-grade SSDs, a BaM system can support application performance that is competitive against a much more expensive DRAM-only solution, and the reduction in I/O amplification can yield significant performance benefit."
"BaM通过使GPU线程能够按需读取或写入少量数据来缓解I / O流量放大,这取决于计算,"Nvidia的文件写道。"我们表明,在GPU上运行的BaM基础设施软件可以以足够高的速率识别和通信细粒度访问,以充分利用底层存储设备,即使使用消费级SSD,BaM系统也可以支持与更昂贵的仅DRAM解决方案竞争的应用程序性能,并且I / O放大的减少可以产生显着的性能优势。
——
To a large degree, Nvidia's BaM is a way for GPUs to obtain a large pool of storage and use it independently from the CPU, which makes compute accelerators much more independent than they are today.
在很大程度上,Nvidia的BaM是GPU获取大量存储并独立于CPU使用它的一种方式,这使得计算加速器比现在更加独立。
——
Astute readers will remember that AMD attempted to wed GPUs with solid-state storage with its Radeon Pro SSG graphics card several years ago. While bringing additional storage to a graphics card allows the hardware to optimize access to large datasets, the Radeon Pro SSG board was designed purely as a graphics solution and was not designed for complex compute workloads. Nvidia, IBM, and others are taking things a step further with BaM.
精明的读者会记得,几年前,AMD曾试图将GPU与固态存储相结合,并推出Radeon Pro SSG显卡。虽然为图形卡提供额外的存储空间可以使硬件优化对大型数据集的访问,但Radeon Pro SSG板纯粹是作为图形解决方案设计的,而不是为复杂的计算工作负载而设计的。Nvidia,IBM和其他公司正在通过BaM更进一步。 |
 310112100042806
310112100042806


 发表于 2022-3-16 09:24
发表于 2022-3-16 09:24