|
5600| 0
|
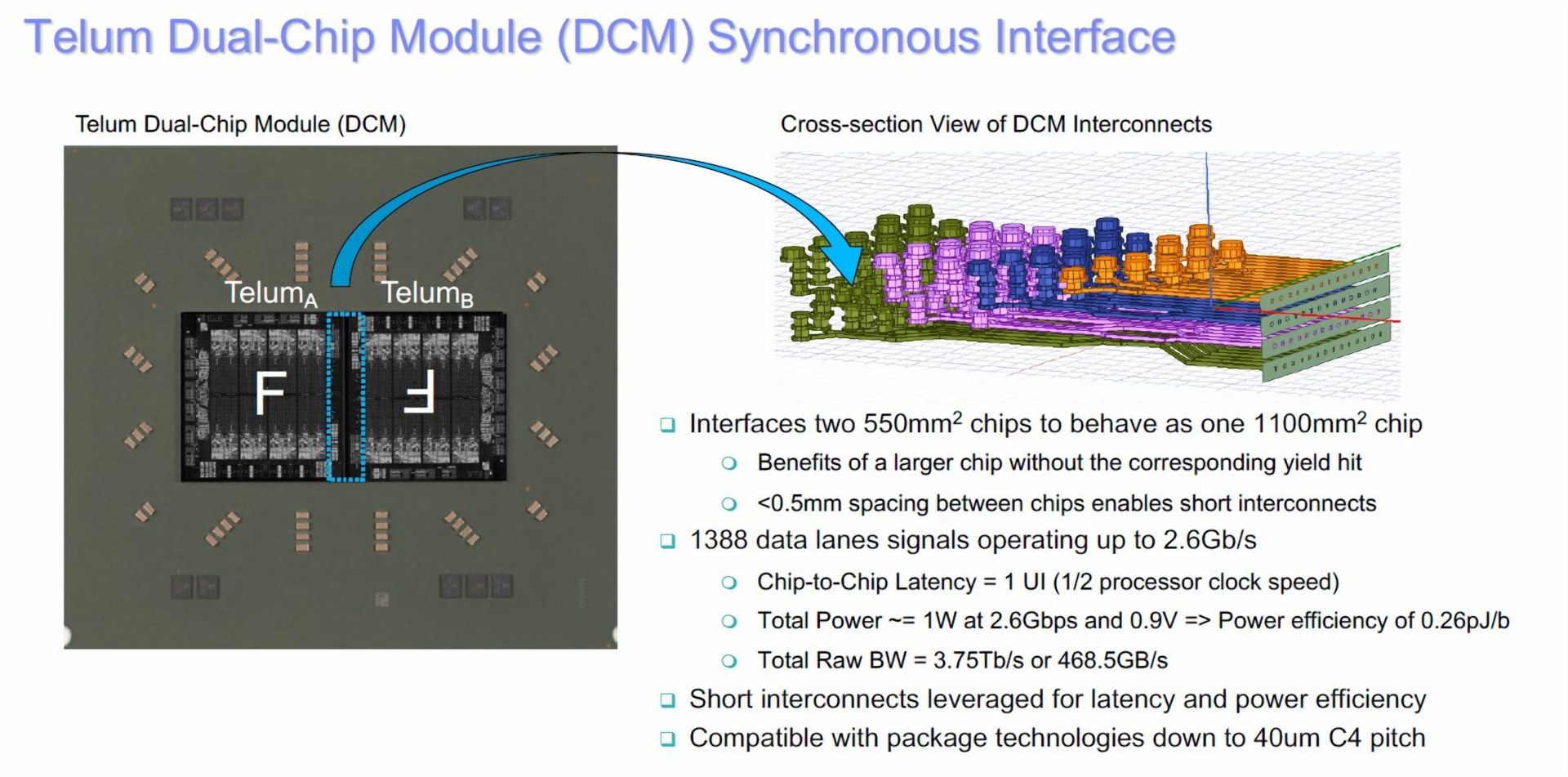
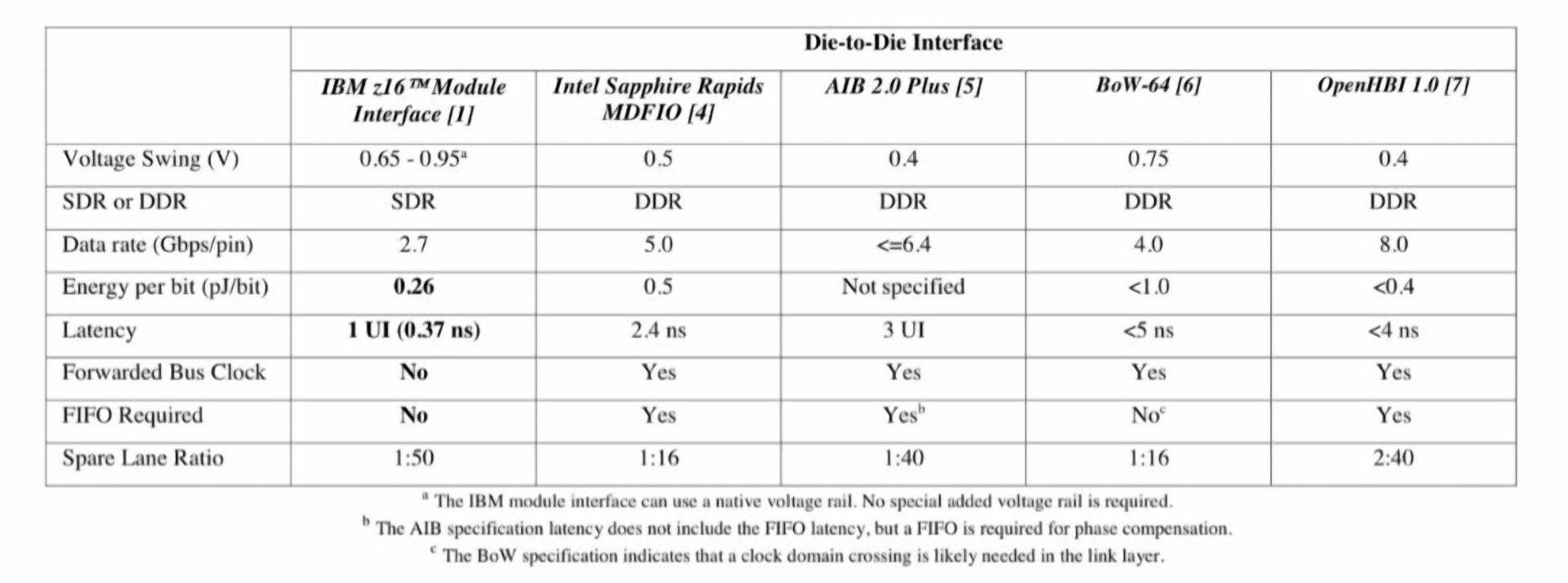
[CPU] IBM Z16 Telum使用的chiplet互联技术 |
| ||
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-4-20 00:38 , Processed in 0.191499 second(s), 4 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.

 发表于 2022-8-21 18:32
发表于 2022-8-21 18:32