架构特点
本代RTX 40系列采用了名为Ada Lovelace的新架构.带来新的全景光线追踪,着色器指令重排序和DLSS 3等提升.
拥有新的流式处理器,新一代RT Core,新一代Tensor Core,全新的光流加速器和新一代视频引擎.
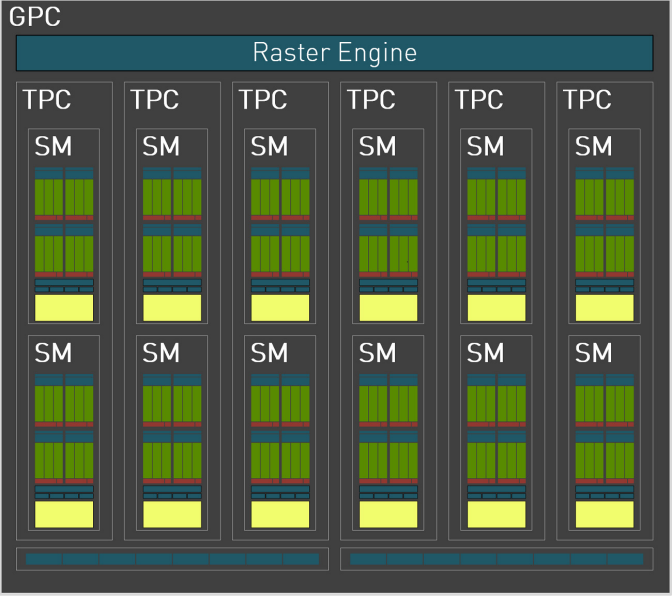
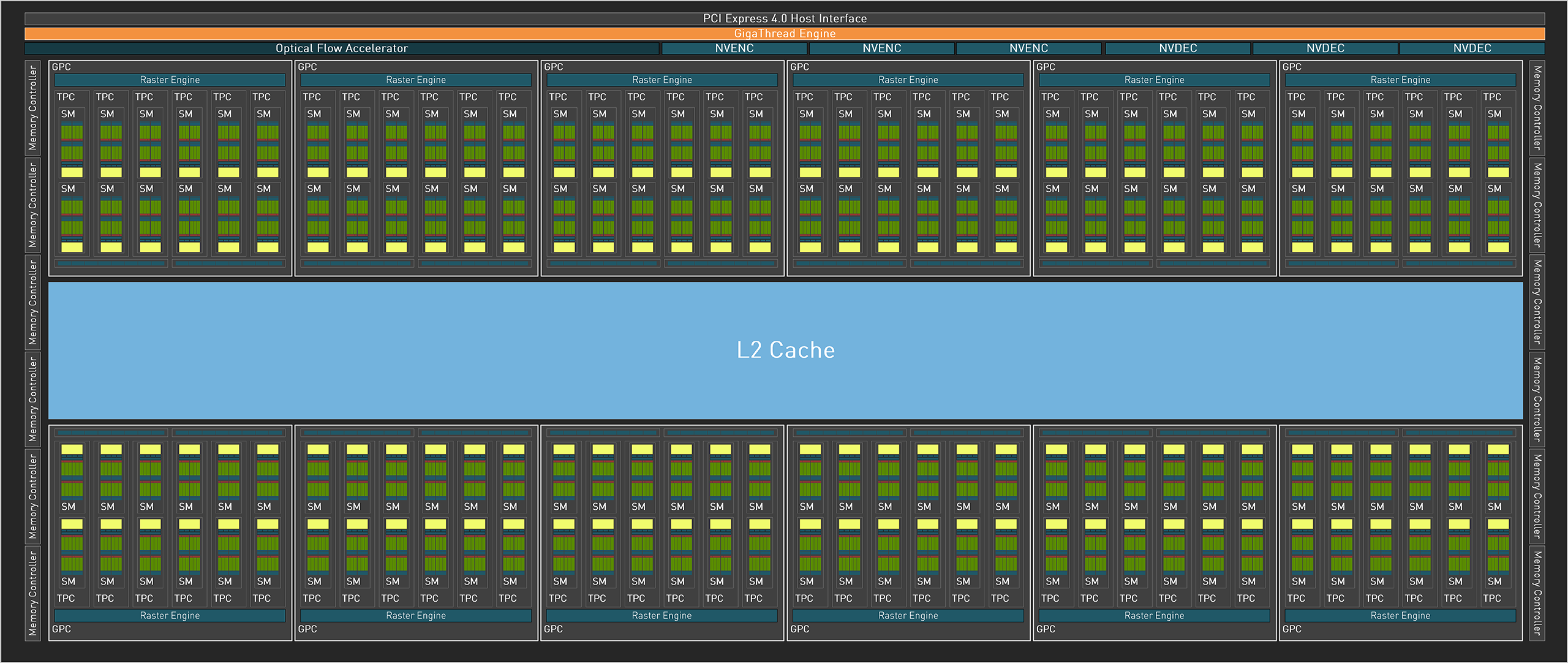
核心的整体层级和前代类似,依旧是GPC-TPC-SM. 其中的规模最大的核心AD102的完整版共拥有12组GPC,72组TPC(每组GPC包含6组TPC),144组SM(每组TPC包含两组SM).对照RTX 30系列上采用的Ampere架构中规模最大的GA102核心.规模上增加了约70%.
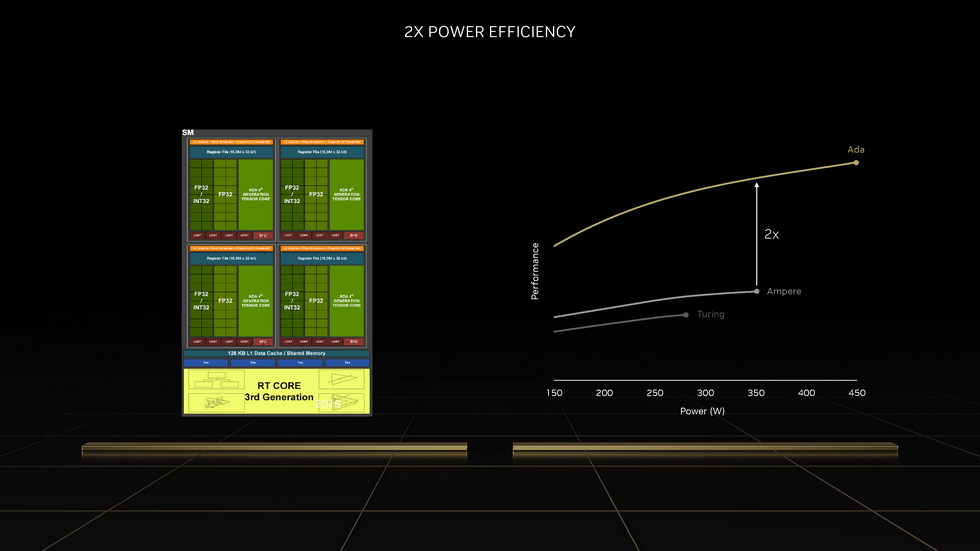
具体到每一组GPC和TPC以及SM的数量构成,Ada Lovelace和Ampere保持一致.不过其中的RT Core和Tensor Core分别升级到了第三代和第四代.其中第四代 Tensor Cores 主要改进点在于新增FP8引擎.
规模的暴增离不开先进工艺的扶持.虽然随着前代旗舰RTX 3090 Ti和新一代电源规格的落定,旗舰显卡的功耗上限从十年间约定俗成的250W提高到了450W,且已为600W做好了规划,但暴露出的则是能耗比正在逐渐失控.于是这次NVIDIA在RTX 40上重新用回了当下最先进的工艺之一:定制版的TSMC 4N.宣称可以达到两倍能耗比的提升.
AD102完整版框图.
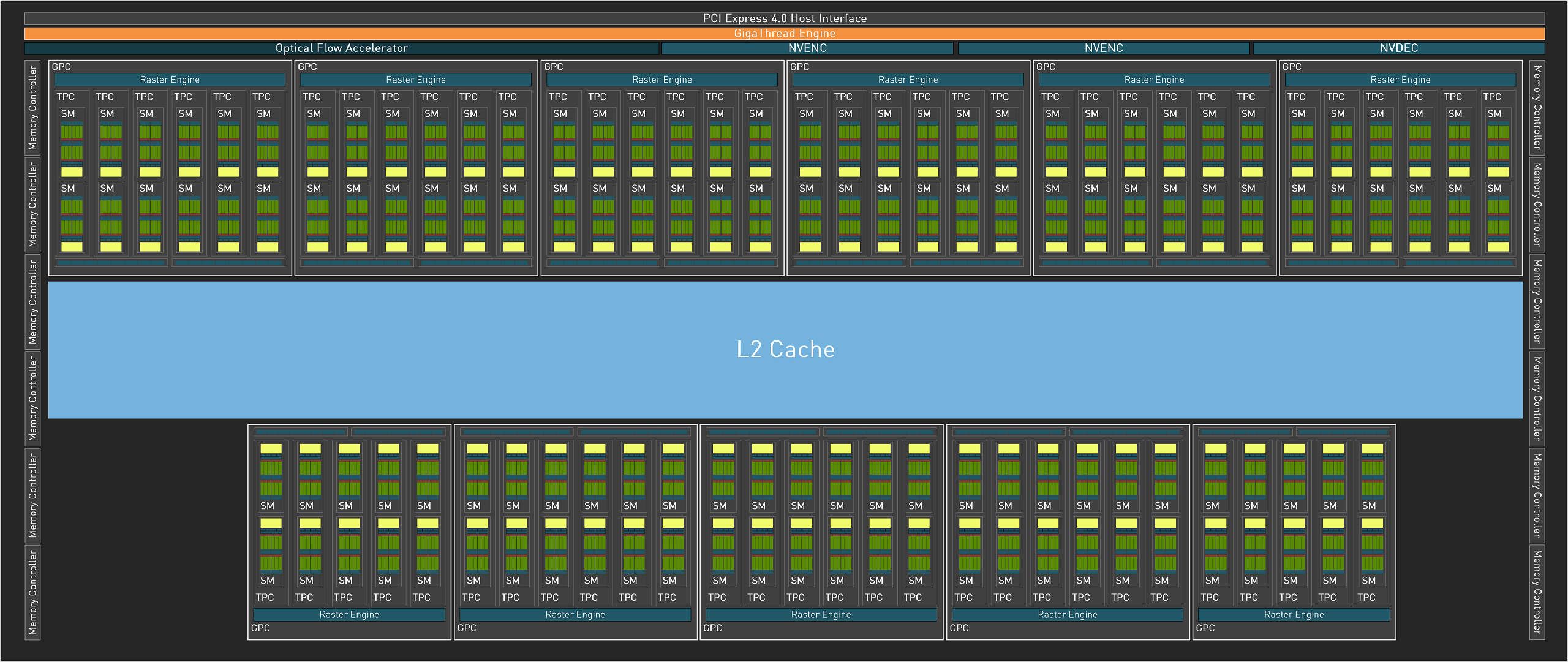
当然人称刀客的黄老板肯定不会那么好心在RTX 4090上就使用完整版AD102.,RTX 4090使用的AD102-300版本核心屏蔽了1组GPC,而剩余的11组GPC中,又有两组GPC中各屏蔽了其中的一组TPC.整体规模被砍了大约1/9.
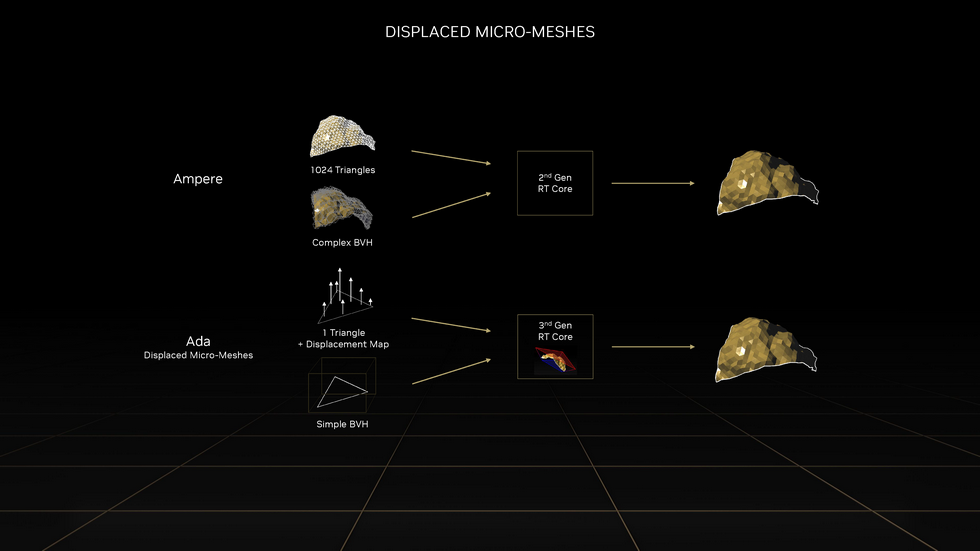
而第三代RT Core重要的改进点在引入Displaced Micro-Meshes和Opacity Micro-Maps.
Displaced Micro-Meshes可以简化需要计算的三角形数量和,提升BVH构建的性能.极大减少了存储占用和运算开销.
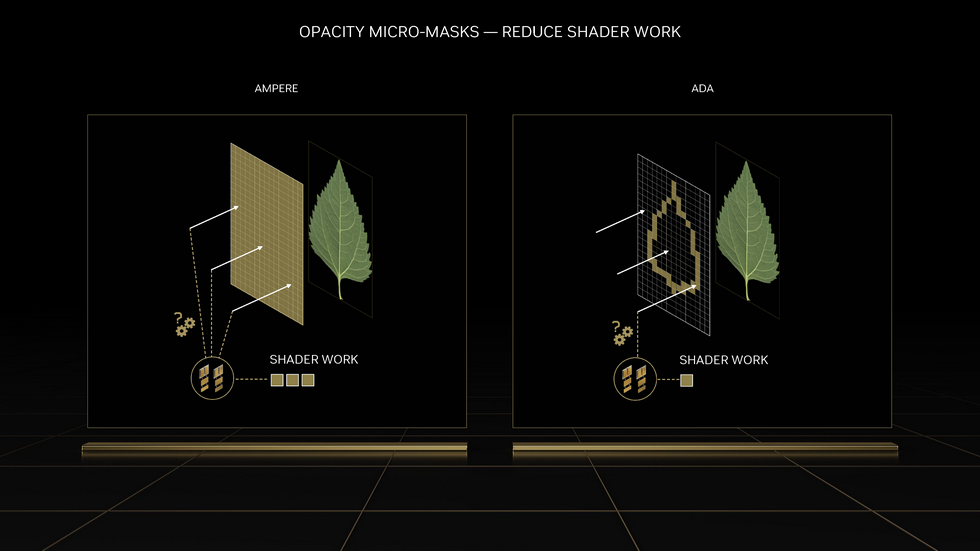
Opacity Micro-Map则助于更准确地避开对不透明区域的计算,同样大幅节省了开销.
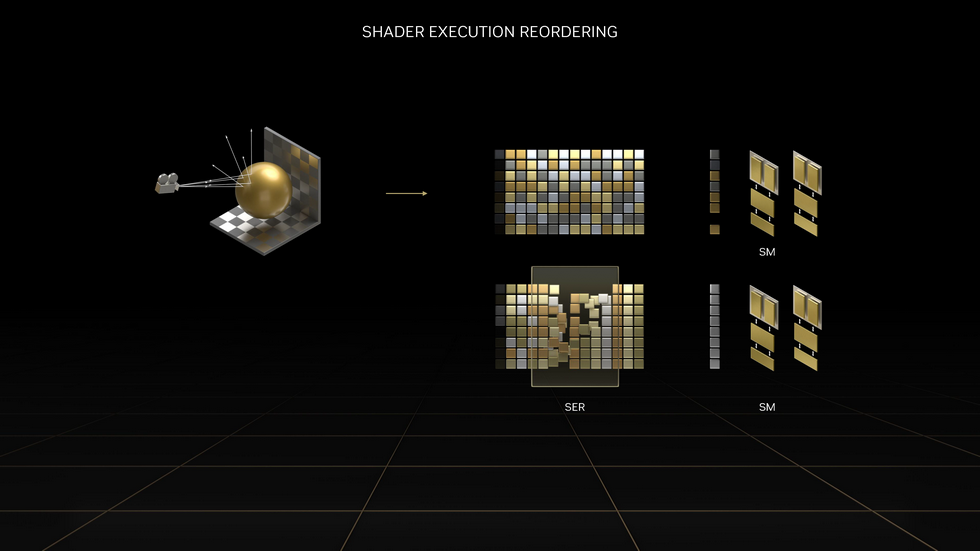
另一项新特性则是SER(Shader Execution Reordering,着色器执行重排序),并行执行的效率可大幅提高.
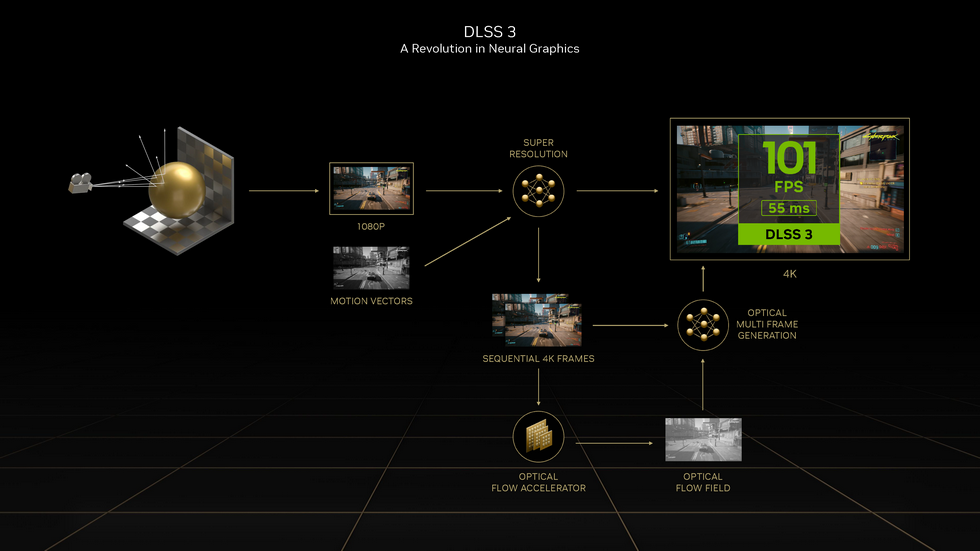
DLSS 3也是本代新增特性.如果说DLSS 2 Super Resolution的核心想法是”补分辨率”,那DLSS 3 Frame Generation的核心想法则是“补帧”.两者并不冲突,可结合使用. 而为了使“补帧”的效果更为准确,其中的一环则需要依靠借助于更强的光流加速器,也正是Ada Lovelace新架构在硬件上的提升之一
而“补帧”带来的延迟问题,则依靠NVIDIA Reflex功能予以缓解.
当然,这一功能也需要游戏做针对性适配后才能起效.目前画饼了的游戏数量超过35款.
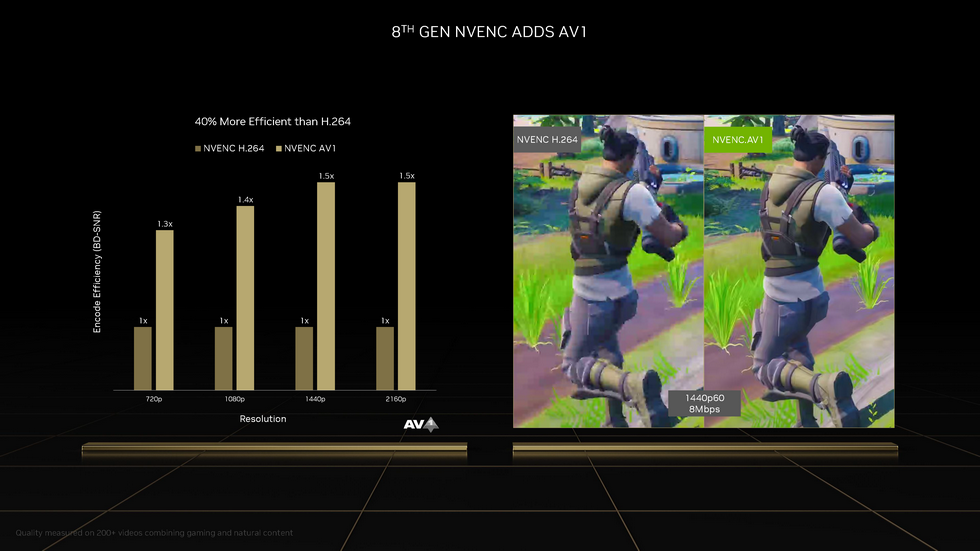
编解码的支持度上,NVENC编码器也来到了第八代.新增了AV1编码和双编码器支持.
|
nApoleon: 其实是测试误差.
微臣辜负众望: 这么小的PCB非要弄这么大的散热,实在欣赏不来,包括公版
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-4-11 02:22 , Processed in 0.607139 second(s), 9 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.